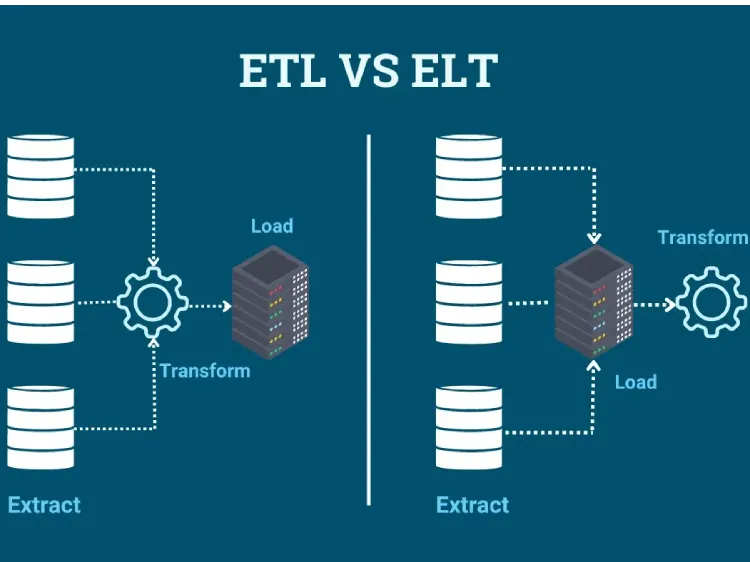
- Application Services
- Next-Gen App Development
- Mobile Application Development
- Modernization
-
-
- Integration ServicesGet seamless integration of various 3rd party services or existing systems for smooth operations of your mobile apps
- Cross PlatformsExcellent user experience and functionality of native apps with multi-platform compatibility
- Legacy System Modernization ServicesLegacy system modernization empowers organizations so that they can work more efficiently and intelligently.
-
-
- DevOps
- Software Testing
-
-
- AI Enabled TestingLeverage AI for testing the quality of your software products
- Functional TestingAutomated Functional Testing for improved quality & faster go-to-market
- STQC CertificationQuality, Excellence, and Innovation – The Hallmarks of Suma Soft
- Performance TestingEliminate performance bottlenecks of business-critical apps to run under expected, peak loads
-
- Scriptless Automation SolutionsFast, reliable, and easy testing with our “Ready-to-Deploy” automation framework
- Devops TestingOptimize testing in CI/CD pipelines for greater agility, efficiency, and quality
- AA CertificationEmpaneled Certifier for Account Aggregator (AA) Ecosystem
- ABDM Ecosystem Sandbox Exit ProcessWe Certify Your API for ABDM Sandbox Integration And Exit Process
-
-
- AI/ML Services
- AI/ML ServicesStay ahead of the curve with our advanced AI/ML capabilities
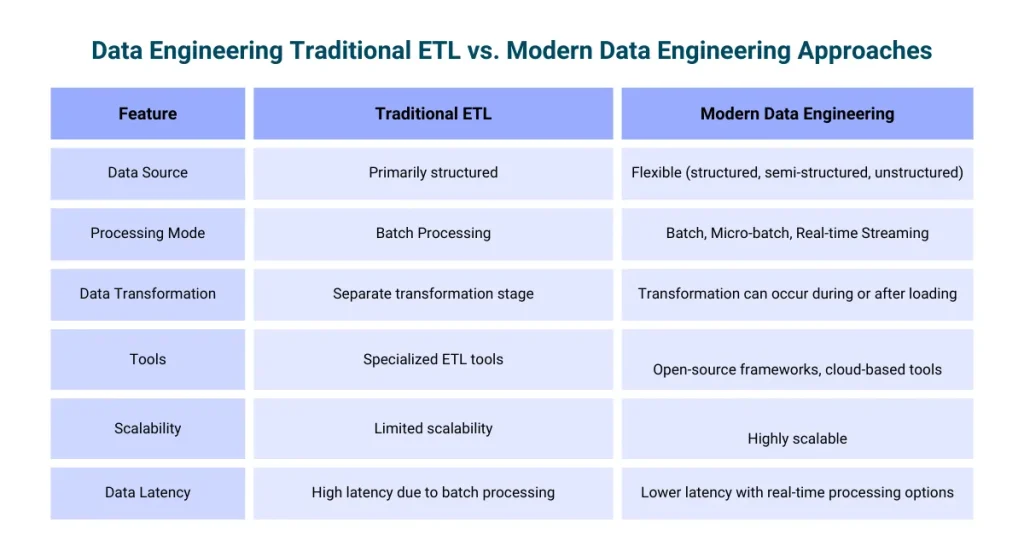
- Data Engineering ServicesDrive data-driven decision-making with our agile and customizable data engineering solutions
- Software Product Engineering ServicesTransform your concepts into market-leading products with our strategic product engineering approach
- VaniePartner with Us for Innovative Web App Solutions!
- Indiastack
- Account AggregatorGet certified using Daksh DEPA Validator to go live on the AA network.
- Ayushman Bharat Digital Mission (ABDM)Get certified using Daksh DEPA Validator to go live on the ABDM network.
- Beckn Protocol ImplementationImplement Beckn protocol to go live on India Stack network.
- ONDC CertificationGet certified using Daksh DEPA Validator to go live on the ONDC network.
- O Rickshaw Pune’s First ONDC Mobility App
- Business Services
- Business Process Management
-
-
- Healthcare BPO ServicesRound the clock coverage for most critical industry
- Logistics BPO & Supply Chain ManagementSmarter supply chains Built for today and ready for tomorrow
- Data Entry ServicesEnsure the accuracy and security of your data with Suma Soft
- Underwriting support servicesStreamline underwriting processes , increase accuracy, reduce risk with expert support services.
- Finance and Accounting ManagementImproving Account Payable and Receivables Through Artificial Intelligence
-
- Logistics BPO ServiceOptimize logistics with efficient operations, reduced costs, and our improved visibility.
- Customer Support ServicesSmart use of technology makes all the difference in CX
- REIT Management ServicesProductivity for You. Transparency for Your Investor
- OCR Outsourcing ServicesAchieve faster, accurate and reliable data capture with OCR outsourcing solutions.
- Claims ManagementState-of-the-art technology to assist in responding to rapidly-evolving claim situations
-
-
- Tech Support
-
-
- Desktop SupportResponsive, Day-to-Day Tech Assistance
- Network SupportCreate a comprehensive network security strategy for protecting the enterprise end-to-end
- Active Directory SupportMinimize the risk of disrupting critical business apps while optimizing the performance of MS infrastructure
- Microsoft Exchange SupportStay on top of imminent threats to achieve a glitch-free network with rapid Microsoft Exchange support
-
- L1 & L2 SupportOptimize performance with round-the-clock technical support cater to your business goals
- Remote MonitoringKeep your IT systems running smoothly and ensure the stability and security of your IT environment for the workforce
- NOCGet unrivaled NOC services & scale immediately to enhance your bottom-line profitability with 24*7 services
-
-
- Hyperautomation
-
- Cyber Security
-
-
- AssessmentTest your applications and networks to identify & fix vulnerabilities exposing your sensitive assets
- Cloud SecurityIntelligence and expertise providing a new level of cyber-immunity
- Managed SecurityComprehensive security architecture with flexible enforcement for advanced protection
- Digital ForensicsEmpower your organization to access, manage and leverage Digital Data
-
-
- ServiceNow
- ServiceNow Managed ServicesOngoing ServiceNow support and optimization for peak performance.
- ServiceNow Integration ServicesConnect systems with seamless ServiceNow integration solutions.
- ServiceNow Implementation ServicesExpert ServiceNow implementation for customizable business solutions.
- ServiceNow Migration ServiceAchieve seamless platform transitions with smooth ServiceNow migration.
- ServiceNow Consulting ServicesStrategic ServiceNow consulting for optimal platform utilization.
- ServiceNow ITBM ImplementationImplement ITBM for strategic IT planning and execution.
- ServiceNow ITSM Implementation ServicesPlan and streamline IT service management with expert implementation services.
- ServiceNow Chatbot DevelopmentEnhance user experience with intelligent ServiceNow chatbot solutions.
- ServiceNow CSM ImplementationImprove customer service with efficient ServiceNow CSM implementation.
- ServiceNow GRC ImplementationManage governance, risk, and compliance with ServiceNow GRC.
- ServiceNow Security OperationsStrengthen security posture with ServiceNow security operations management.
- ServiceNow IT Operations Management ServicesOptimize Your IT Operations with automated workflows and efficient service delivery.
- ServiceNow HR Service DeliveryEnhance employee experiences with automated HR service management.
- ServiceNow Financial ManagementStreamline financial operations and improve decision-making with ServiceNow.
- ServiceNow Asset Management ServicesControl IT assets, reduce costs, and ensure compliance with ServiceNow Asset Management.
- Project Portfolio Management ServiceNowPrioritize projects and manage resources for successful delivery.
- Resource Management with ServiceNowStreamline resource allocation for project efficiency and success with ServiceNow Resource Management.
- Business Process Management
- Digital
- Cloud
-
-
- Cloud App Development ServicesGet high security, efficient performance, and excellent operations with cloud apps
- Cloud Testing ServicesDelivering highly polished solutions to help you reduce costs and meet deadlines
- Cloud Migration ServicesA secure cloud single sign-on solution that IT, security, and users will surely love
-
- Enterprise Mobility
- CRM
- Microsoft Dynamics 365 ServicesStreamline business processes with superior BI, automation, and key customer insights
- Custom CRM Development ServicesDigitize processes, enhance everyday managerial activities and engage more customers
- Salesforce Consulting ServicesTransform Your Business with Expert Salesforce Guidance – Elevate Performance and Drive Growth!
- Salesforce testing servicesAchieve end-to-end automation for Salesforce testing
- E-Learning
- Collaboration
- Dusmile Platform
- Cloud
- Insights
- Industries
- Industry We Serve
- Banking And FinanceAccelerate your journey with fintech innovation to reshape customer experience
- GovernmentFully-managed environment for Government, Built for security and compliance
- E-CommerceBest-of-breed technologies to enhance CX and increase revenue to maximize business needs
- E-LearningReimaging education – from remote to hybrid learning
- Logistics & DistributionChanging the landscape of supply chain management
- AutomotiveRevolutionizing automotive development for the digital future
- HealthcareDelivering better experiences, better insights, and better care for better health
- ManufacturingLeverage our deep expertise to modernize your manufacturing and industrial technologies and processes.
- Industry We Serve
- About Us
- About Suma Soft
- HistoryDecades of experience and expertise matched with dedicated professionals.
- LeadershipA leadership that drives Suma Soft to meet its overall goals.
- CertificationsOur recognition as a trusted technology company for orchestrating a successful business transformation
- Our PartnersBringing together the best technologies and practices to offer a prosperous digital future
- Annual ReturnSuma Soft’s Yearly Financial Annual Return Report
- About Suma Soft
- Careers
- Contact Us